sklearn package에는 분류(classifcation) 모형의 테스트를 위해 여러가지 데이터를 생성하는 함수를 제공해준다. 그 중 make_classification을 통한 가상의 데이터를 생성하는 코드를 정리해 보고자 한다.
make_classification
a. 인수
- n_samples : 표본 데이터의 수(default=100)
- n_features : 독립 변수의 수(default=20)
- n_informative : 독립 변수 중 종속 변수와 상관 관계가 있는 성분의 수(default=2)
- n_redundant : 독립 변수 중 다른 독립 변수의 선형 조합으로 나타나는 성분의 수(default=2)
- n_classes : 종속 변수의 클래스 수(default=2)
- n_clusters_per_class : 클래스 당 클러스터의 수(default=2)
- weights : 각 클래스에 할당된 표본 수
- random_state : 난수 발생 시드
b. 반환값
- X : [n_samples, n_features] 크기의 배열(독립변수)
- y : [n_samples] 크기의 배열(종속변수)
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import warnings
warnings.filterwarnings('ignore')가상 데이터 생성
1. 1개의 feature, 2개의 class 생성
## n_features = 1, n_class = 2(default)
X, y = make_classification(n_features=1, n_informative=1, n_redundant=0, n_classes=2, n_clusters_per_class=1,random_state=4)
print(X.shape) ## 독립변수 ## [n_samples, n_features] 크기의 배열
print(y.shape) ## 종속변수 ## [n_samples] 크기의 배열
## 결과
## (100, 1)
## (100, )
dataframe을 확인해보면 다음과 같다.
df= pd.DataFrame({'X': X[:,0], 'y':y})
df
다음은 그래프를 통해서 생성된 데이터를 확인해 보고자 한다. 그래프 그리기 전 한글 깨짐 방지와 폰트 설정을 해주었다.
font = {'family' : 'normal',
'weight' : 'bold',
'size' : 15}
matplotlib.rc('font', **font)
matplotlib.rc('text', color='black')
matplotlib.rc('axes', labelcolor='white')
matplotlib.rc('xtick', color='white')
matplotlib.rc('ytick', color='white')
## 한글깨짐
matplotlib.rcParams['font.family'] ='Malgun Gothic'
matplotlib.rcParams['axes.unicode_minus'] =Falseplt.figure(figsize=(7,7), facecolor='black')
plt.grid('whitegrid')
sns.scatterplot(X[:,0], y, marker='o', c=y, s=100, edgecolor='k',linewidth=2)
plt.xticks(color='white')
plt.yticks(color='white')
plt.xlabel('X',color='white')
plt.ylabel('y',color='white')
plt.title('1개의 독립변수를 가진 가상의 데이터',color='white')
plt.figure(figsize=(10,5), facecolor='black')
plt.grid('white')
sns.distplot(X[y == 0], label="y=0")
sns.distplot(X[y == 1], label="y=1")
plt.xticks(color='white')
plt.yticks(color='white')
plt.ylabel('Density',color='white')
plt.legend()
plt.show()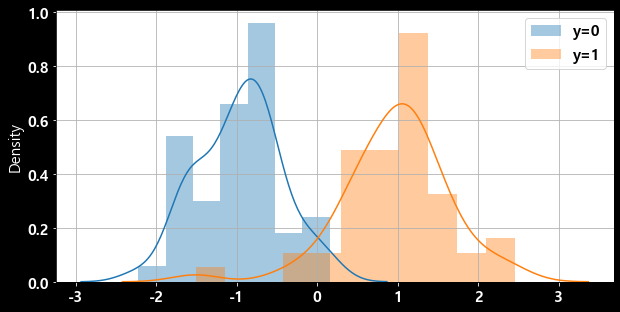
2. 2개의 feature, 2개의 class - target과 상관관계가 있는 변수는 1개
## n_features = 2, n_class = 2(default), n_informative = 1
X, y = make_classification(n_features=2, n_informative=1, n_redundant=0, n_clusters_per_class=1, random_state=4)
print(X.shape)
print(y.shape)
### 결과값
### (100, 2)
### (100, )feature 및 target의 상관관계 확인 결과, 두 번째 feature(x2)와 target(y)는 강한 양의 상관관계가 있는 반면, 첫 번째 feature(x1)와 target(y)는 상관관계가 없다.
plt.figure(figsize=(7,7), facecolor='black')
test_heatmap = sns.heatmap(cor.values,# 데이터
cbar = True, # 오른쪽 컬러 막대 출력 여부
annot = True, # 차트에 상관계수 값을 보여줄 것인지 여부
annot_kws={'size' : 20}, # 숫자 출력 시 숫자 크기 조절
fmt = '.3f', # 숫자의 출력 소수점자리 개수 조절
square = 'True', # 차트를 정사각형으로 할 것인지
yticklabels=['X_1','X_2','y'], # y축에 컬럼명 출력
xticklabels=['X_1','X_2','y']) # x축에 컬럼명 출력
plt.tight_layout()
plt.show()
데이터 시각화를 통해 생성된 가상의 데이터의 분포를 확인해 보고자 한다.
plt.figure(figsize=(7,7))
plt.grid('whitegrid')
sns.scatterplot(X[:,0], X[:,1], marker='o', c=y, s=100, edgecolor='k',linewidth=2)
plt.xticks(color='white')
plt.yticks(color='white')
plt.xlabel('X_1',color='white')
plt.ylabel('X_2',color='white')
plt.title('하나의 독립변수만 클래스와 상관관계가 있는 가상의 데이터',color='white')
plt.figure(figsize=(10,5))
plt.subplot(121)
sns.distplot(X[y == 0, 0], label="y=0")
sns.distplot(X[y == 1, 0], label="y=1")
plt.legend()
plt.xlabel("x_1")
plt.ylabel('Density')
plt.subplot(122)
sns.distplot(X[y == 0, 1], label="y=0")
sns.distplot(X[y == 1, 1], label="y=1")
plt.legend()
plt.xlabel("x_2")
plt.show()
3. 두 개의 feature, 2개의 class -> target과 상관관계가 있는 변수 2개
이번에는 sample 수를 500개로 증가시켜서 해보았다.
## n_samples = 500, n_features = 2, n_class = 2(default), n_informatvie = 2
X, y = make_classification(n_samples=500, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=6)
df = pd.DataFrame({'X_1': X[:,0], 'X_2': X[:,1], 'y' : y})
cor = df.corr()
plt.figure(figsize=(7,7), facecolor='black')
test_heatmap = sns.heatmap(cor.values,# 데이터
cbar = True, # 오른쪽 컬러 막대 출력 여부
annot = True, # 차트에 상관계수 값을 보여줄 것인지 여부
annot_kws={'size' : 20}, # 숫자 출력 시 숫자 크기 조절
fmt = '.3f', # 숫자의 출력 소수점자리 개수 조절
square = 'True', # 차트를 정사각형으로 할 것인지
yticklabels=['X_1','X_2','y'], # y축에 컬럼명 출력
xticklabels=['X_1','X_2','y']) # x축에 컬럼명 출력
plt.tight_layout()
plt.show()위의 그림에서 볼 수 있듯이 두 개의 feature(x_1, x_2) 모두 target(y)와 양의 상관관계가 있는 것을 알 수 있다.

plt.figure(figsize=(7,7), facecolor='black')
plt.grid('whitegrid')
sns.scatterplot(X[:,0], X[:,1], marker='o', c=y, s=100, edgecolor='k',linewidth=2)
plt.xticks(color='white')
plt.yticks(color='white')
plt.xlabel('X_1',color='white')
plt.ylabel('X_2',color='white')
plt.title('두개의 독립변수 모두 클래스와 상관관계가 있는 가상의 데이터',color='white')
한 개의 feature만 target 값과 상관관계가 있는 데이터에서 feature 간의 산점도와 두 개의 feature 모두 target 값과 상관관계가 있는 데이터에서 feature 간의 산점도 분포가 다른 것을 확인할 수 있다.
마지막으로, 다중 클래스를 형성한 데이터를 확인해 보고자 한다.
4. 다중 클래스 - 3개의 feature, 3개의 class
## n_samples = 1000, n_features = 3, n_class = 3
X, y = make_classification(n_samples=1000, n_features=3, n_informative=2, n_redundant=0, n_clusters_per_class=1, n_classes=3, random_state=6)
df = pd.DataFrame({'X_1':X[:,0], 'X_2':X[:,1], 'X_3':X[:,2], 'y':y})
cor = df.corr()
plt.figure(figsize=(7,7), facecolor='black')
test_heatmap = sns.heatmap(cor.values,# 데이터
cbar = True, # 오른쪽 컬러 막대 출력 여부
annot = True, # 차트에 상관계수 값을 보여줄 것인지 여부
annot_kws={'size' : 20}, # 숫자 출력 시 숫자 크기 조절
fmt = '.3f', # 숫자의 출력 소수점자리 개수 조절
square = 'True', # 차트를 정사각형으로 할 것인지
yticklabels=['X_1','X_2','y'], # y축에 컬럼명 출력
xticklabels=['X_1','X_2','y'],
cmap='Pastel1') # x축에 컬럼명 출력
plt.tight_layout()
plt.show()
데이터 시각화를 통해 가상의 데이터를 확인해 보면 다음과 같다.
sns.pairplot(df, hue='y')