1. 정의
여러가지 모델들의 예측값을 최종 모델의 학습 데이터로 사용하여 예측하는 방법이다. 즉, Stacking이란 개별적인 여러 알고리즘을 서로 결합해 예측 결과를 도출하는 것이며 이를 기반으로 다시 예측하는 것이다.
2. 특징
- 성능 개선을 위해 개발되었지만, 언제나 성능 개선이 이루어지는 것은 아님.
- 개별 모델(base model)들의 성능이 좋아야 하며, 모델에서 나온 예측치끼리 uncorreated 되어야 한다.
- 개별 모델(base model)의 수가 2개 이상이어야 함.
3. Stacking에서의 단계별 모델
- Base Models : 학습 데이터를 이용해 모델을 학습시키고 예측치들을 합침
- Meta Model : base models의 예측치를 합쳐 개선된 성능을 가진 모델 생성
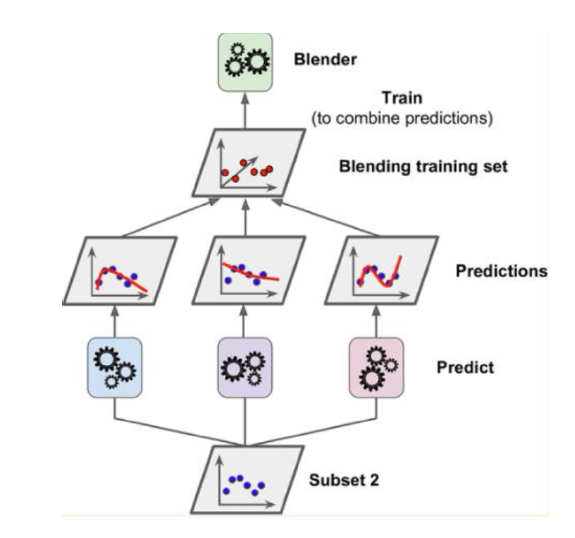
[여러 개별 모델의 예측 데이터를 각각 스태킹 형태로 결합해, 최종 메타 모델의 data set을 만드는 것이 중요]
4. 이점 및 목표
- 이점 : regression/classification에서 성능이 좋은 다양한 모델의 기능을 활용 + 단일 모델보다 성능이 더 좋은 예측 가능
- 목표 : 스태킹 앙상블 성능 > 어떤 단일 기본 모델 성능
5. 스태킹의 구조
- 스태킹 : 결합기가 개별 학습기를 결합하도록 훈련하는 일반적인 절차
- 개별 학습기 = 1단계 학습기
- 결합기 = 2단계 학습기 or 메타 학습기
- 스태킹 모델 구조 = Level 0 models(=기본 모델) + Level 1 model(=메타 모델)
- 기본 모델 : 모델을 훈련 데이터에 적합 + 예측이 컴파일 됨
- 메타 모델 : 기본 모델의 예측을 잘 결합하는 방법을 학습
[Base Model]

[Meta Model]

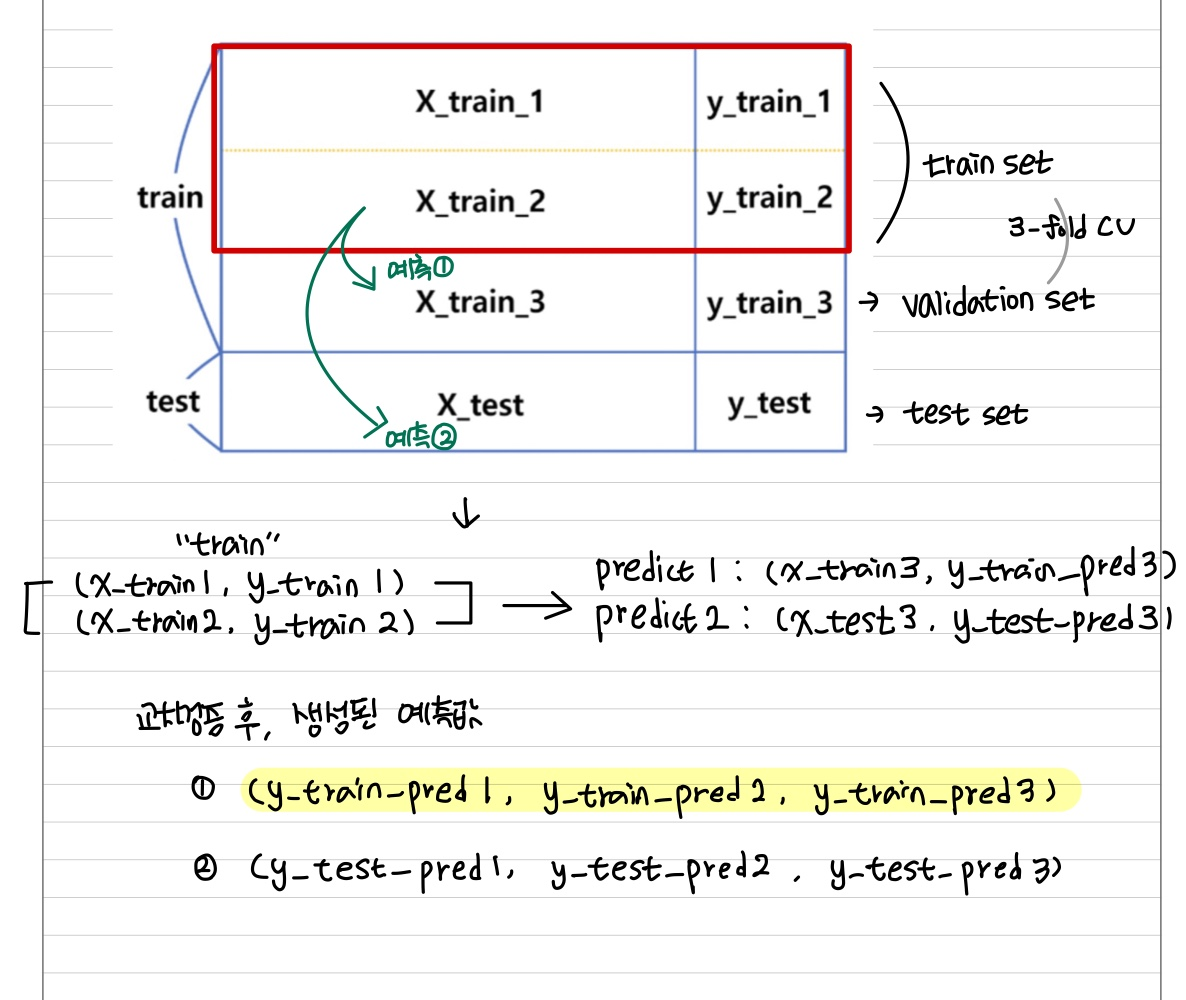
[Stacking을 사용하기 위해서는 반복되는 k-fold cv 사용하여 평가]
def get_stacking():
# define the base models
level0 = list()
level0.append(('lr', LogisticRegression()))
level0.append(('knn', KNeighborsClassifier()))
level0.append(('cart', DecisionTreeClassifier()))
level0.apend(('svm', SVC()))
level0.append(('bayes', GaussianNB()))
level1 = LogisticRegression()
model = StackingClassifier(estimators=level0, final_estimator=level1, cv=5)
return modeldef evaluate_model(model,X,y):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='f1_score', cv=cv)
return scores'Machine Learning > Ensemble' 카테고리의 다른 글
| Ensemble Member Selection (1) | 2022.10.17 |
|---|---|
| Voting Ensemble & Weighted Average Ensemble (1) | 2022.10.17 |
