2024년 3월에 푼 프로그래머스 코딩문제("코딩테스트 공부 목적")
본 글은 프로그래머스 코딩테스트 문제에서 푼 문제를 정리한 글입니다.
1. [Lv1] 개인정보 수집 유효기간(정답률 44%, 2023 KAKAO BLIND RECRUITMENT)
[문제 설명]
고객의 약관 동의를 얻어서 수집된 1~n번으로 분류되는 개인정보 n개가 있습니다. 약관 종류는 여러 가지 있으며 각 약관마다 개인정보 보관 유효기간이 정해져 있습니다. 당신은 각 개인정보가 어떤 약관으로 수집됐는지 알고 있습니다. 수집된 개인정보는 유효기간 전까지만 보관 가능하며, 유효기간이 지났다면 반드시 파기해야 합니다.
예를 들어, A라는 약관의 유효기간이 12 달이고, 2021년 1월 5일에 수집된 개인정보가 A약관으로 수집되었다면 해당 개인정보는 2022년 1월 4일까지 보관 가능하며 2022년 1월 5일부터 파기해야 할 개인정보입니다.
당신은 오늘 날짜로 파기해야 할 개인정보 번호들을 구하려 합니다.
모든 달은 28일까지 있다고 가정합니다.
[예시]
다음은 오늘 날짜가 2022.05.19일 때의 예시입니다.
약관 종류유효기간
| 약관 종류 | 유효기간 |
| A | 6달 |
| B | 12달 |
| C | 3달 |
| 번호 | 개인정보 수집 일자 | 약관 종류 |
| 1 | 2021.05.02 | A |
| 2 | 2021.07.01 | B |
| 3 | 2022.02.19 | C |
| 4 | 2022.02.20 | D |
- 첫 번째 개인정보는 A약관에 의해 2021년 11월 1일까지 보관 가능하며, 유효기간이 지났으므로 파기해야 할 개인정보입니다.
- 두 번째 개인정보는 B약관에 의해 2022년 6월 28일까지 보관 가능하며, 유효기간이 지나지 않았으므로 아직 보관 가능합니다.
- 세 번째 개인정보는 C약관에 의해 2022년 5월 18일까지 보관 가능하며, 유효기간이 지났으므로 파기해야 할 개인정보입니다.
- 네 번째 개인정보는 C약관에 의해 2022년 5월 19일까지 보관 가능하며, 유효기간이 지나지 않았으므로 아직 보관 가능합니다.
따라서 파기해야 할 개인정보 번호는 [1, 3]입니다.
오늘 날짜를 의미하는 문자열 today, 약관의 유효기간을 담은 1차원 문자열 배열 terms와 수집된 개인정보의 정보를 담은 1차원 문자열 배열 privacies가 매개변수로 주어집니다. 이때 파기해야 할 개인정보의 번호를 오름차순으로 1차원 정수 배열에 담아 return 하도록 solution 함수를 완성해 주세요.
[코드]
def solution(today, terms, privacies):
answer = []
dict_ = {i.split()[0]:i.split()[1] for i in terms}
to_year, to_month, to_day = map(int, today.split("."))
##### 보관 가능 기간 저장 #####
for index,value in enumerate(privacies, start=1):
date, privacy = value.split()
year, month, day = map(int, date.split("."))
year += int(dict_[privacy]) // 12
month += int(dict_[privacy]) % 12
if month >= 13:
year += month // 12
month = month % 12
day -= 1
if day==0:
month -= 1; day=28 ## 모든 달의 마지막 일자는 28일
if month == 0:
month = 12; year -= 1
## 유효기간 지났는지 여부 판단
if year < to_year: ## 연도 비교
answer.append(index)
elif year == to_year:
if month < to_month: ## 월 비교
answer.append(index)
elif month == to_month:
if day < to_day:
answer.append(index)
return answer
2. [Lv1] 바탕화면 정(정답률 47%)
[문제 설명]
코딩테스트를 준비하는 머쓱이는 프로그래머스에서 문제를 풀고 나중에 다시 코드를 보면서 공부하려고 작성한 코드를 컴퓨터 바탕화면에 아무 위치에나 저장해 둡니다. 저장한 코드가 많아지면서 머쓱이는 본인의 컴퓨터 바탕화면이 너무 지저분하다고 생각했습니다. 프로그래머스에서 작성했던 코드는 그 문제에 가서 다시 볼 수 있기 때문에 저장해 둔 파일들을 전부 삭제하기로 했습니다.
컴퓨터 바탕화면은 각 칸이 정사각형인 격자판입니다. 이때 컴퓨터 바탕화면의 상태를 나타낸 문자열 배열 wallpaper가 주어집니다. 파일들은 바탕화면의 격자칸에 위치하고 바탕화면의 격자점들은 바탕화면의 가장 왼쪽 위를 (0, 0)으로 시작해 (세로 좌표, 가로 좌표)로 표현합니다. 빈칸은 ".", 파일이 있는 칸은 "#"의 값을 가집니다. 드래그를 하면 파일들을 선택할 수 있고, 선택된 파일들을 삭제할 수 있습니다. 머쓱이는 최소한의 이동거리를 갖는 한 번의 드래그로 모든 파일을 선택해서 한 번에 지우려고 하며 드래그로 파일들을 선택하는 방법은 다음과 같습니다.
- 드래그는 바탕화면의 격자점 S(lux, luy)를 마우스 왼쪽 버튼으로 클릭한 상태로 격자점 E(rdx, rdy)로 이동한 뒤 마우스 왼쪽 버튼을 떼는 행동입니다. 이때, "점 S에서 점 E로 드래그한다"고 표현하고 점 S와 점 E를 각각 드래그의 시작점, 끝점이라고 표현합니다.
- 점 S(lux, luy)에서 점 E(rdx, rdy)로 드래그를 할 때, "드래그 한 거리"는 |rdx - lux| + |rdy - luy|로 정의합니다.
- 점 S에서 점 E로 드래그를 하면 바탕화면에서 두 격자점을 각각 왼쪽 위, 오른쪽 아래로 하는 직사각형 내부에 있는 모든 파일이 선택됩니다.
[예시]
예를 들어 wallpaper = [".#...", "..#..", "...#."]인 바탕화면을 그림으로 나타내면 다음과 같습니다.
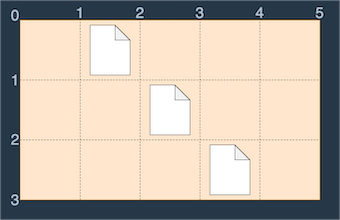
이러한 바탕화면에서 다음 그림과 같이 S(0, 1)에서 E(3, 4)로 드래그하면 세 개의 파일이 모두 선택되므로 드래그 한 거리 (3 - 0) + (4 - 1) = 6을 최솟값으로 모든 파일을 선택 가능합니다.

(0, 0)에서 (3, 5)로 드래그해도 모든 파일을 선택할 수 있지만 이때 드래그 한 거리는 (3 - 0) + (5 - 0) = 8이고 이전의 방법보다 거리가 늘어납니다.
머쓱이의 컴퓨터 바탕화면의 상태를 나타내는 문자열 배열 wallpaper가 매개변수로 주어질 때 바탕화면의 파일들을 한 번에 삭제하기 위해 최소한의 이동거리를 갖는 드래그의 시작점과 끝점을 담은 정수 배열을 return하는 solution 함수를 작성해 주세요. 드래그의 시작점이 (lux, luy), 끝점이 (rdx, rdy)라면 정수 배열 [lux, luy, rdx, rdy]를 return하면 됩니다.
[입출력 예]
| wallpaper | result |
| [".#...", "..#..", "...#."] | [0, 1, 3, 4] |
| ["..........", ".....#....", "......##..", "...##.....", "....#....."] | [1, 3, 5, 8] |
| [".##...##.", "#..#.#..#", "#...#...#", ".#.....#.", "..#...#..", "...#.#...", "....#...."] | [0, 0, 7, 9] |
| ["..", "#."] | [1, 0, 2, 1] |
[코드]
def solution(wallpaper):
answer = []
h, w = len(wallpaper), len(wallpaper[0])
## 파일이 존재하는 위치 찾기
row = []; col = []
for i in range(h):
for j,k in enumerate(wallpaper[i]):
if "#"==k:
row += [i]; col += [j]
answer = [min(row), min(col), max(row)+1, max(col)+1]
return answer
3. [Lv1] [PCCE 기출문제] 10번 / 데이터 분석(정답률: 49%)
[문제]
AI 엔지니어인 현식이는 데이터를 분석하는 작업을 진행하고 있습니다. 데이터는 ["코드 번호(code)", "제조일(date)", "최대 수량(maximum)", "현재 수량(remain)"]으로 구성되어 있으며 현식이는 이 데이터들 중 조건을 만족하는 데이터만 뽑아서 정렬하려 합니다.
예를 들어 다음과 같이 데이터가 주어진다면
data = [[1, 20300104, 100, 80], [2, 20300804, 847, 37], [3, 20300401, 10, 8]]이 데이터는 다음 표처럼 나타낼 수 있습니다.
| code | date | maximum | remain |
| 1 | 20300104 | 100 | 80 |
| 2 | 20300804 | 847 | 37 |
| 3 | 20300401 | 10 | 8 |
주어진 데이터 중 "제조일이 20300501 이전인 물건들을 현재 수량이 적은 순서"로 정렬해야 한다면 조건에 맞게 가공된 데이터는 다음과 같습니다.
data = [[3,20300401,10,8],[1,20300104,100,80]]정렬한 데이터들이 담긴 이차원 정수 리스트 data와 어떤 정보를 기준으로 데이터를 뽑아낼지를 의미하는 문자열 ext, 뽑아낼 정보의 기준값을 나타내는 정수 val_ext, 정보를 정렬할 기준이 되는 문자열 sort_by가 주어집니다.
data에서 ext 값이 val_ext보다 작은 데이터만 뽑은 후, sort_by에 해당하는 값을 기준으로 오름차순으로 정렬하여 return 하도록 solution 함수를 완성해 주세요. 단, 조건을 만족하는 데이터는 항상 한 개 이상 존재합니다.
[제한사항]
- 1 ≤ data의 길이 ≤ 500
- data[i]의 원소는 [코드 번호(code), 제조일(date), 최대 수량(maximum), 현재 수량(remain)] 형태입니다.
- 1 ≤ 코드 번호≤ 100,000
- 20000101 ≤ 제조일≤ 29991231
- data[i][1]은 yyyymmdd 형태의 값을 가지며, 올바른 날짜만 주어집니다. (yyyy : 연도, mm : 월, dd : 일)
- 1 ≤ 최대 수량≤ 10,000
- 1 ≤ 현재 수량≤ 최대 수량
- ext와 sort_by의 값은 다음 중 한 가지를 가집니다.
- "code", "date", "maximum", "remain"
- 순서대로 코드 번호, 제조일, 최대 수량, 현재 수량을 의미합니다.
- val_ext는 ext에 따라 올바른 범위의 숫자로 주어집니다.
- 정렬 기준에 해당하는 값이 서로 같은 경우는 없습니다.
[입출력 예]
| data | ext | val_ext | sort_by | result |
| [[1, 20300104, 100, 80], [2, 20300804, 847, 37], [3, 20300401, 10, 8]] | "date" | 20300501 | "remain" | [[3,20300401,10,8],[1,20300104,100,80]] |
[코드]
def date(date1, date2, index):
year1 = data1[:4]; month1 = data1[4:6]; day1 = data1[6:]
year2 = data2[:4]; month2 = data2[4:6]; day2 = data2[6:]
if year1 > year2:
return index
elif year1 == year2:
if month1 > month2:
return index
elif month1 == month2:
return index
def solution(data, ext, val_ext, sort_by):
### data에서 정보 뽑아내기 ###
dict_ = {'code':0, "date":1, "maximum":2, "remain":3}; number = dict_[ext]
list_ = [value[number] for value in data]
### val_ext와 비교하기 ### => date인 경우와 아닌 경우 나눠서 비교하기
answer = []
if number==1:
for index, value in enumerate(list_):
answer.append(data[date(val_ext, value, index)])
else:
for index, value in enumerate(list_):
if val_ext > value:
answer.append(data[index])
### sort_by를 기준으로 오름차순 정렬하기 ###
number2 = dict_[sort_by]
answer.sort(key= lambda x: x[number2])
return answer'Coding Study' 카테고리의 다른 글
| Depth First Search(DFS) & Breath First Search(BFS) (0) | 2024.05.14 |
|---|---|
| [## 프로그래머스 coding study ##: 2024.04] (0) | 2024.04.01 |
| [## 프로그래머스 coding study ##: 2024.02] (2) | 2024.02.19 |
| [## 프로그래머스 coding study ##: 2024.01] (1) | 2024.01.05 |
| [## 프로그래머스 coding study ## : 2023.12] (0) | 2023.12.02 |



