Overview
Diffusion model은 대표적인 이미지 생성 모델(Image Generative Model)입니다. "Diffusion"이 "확산" 현상을 의미하듯이
입력 데이터에 노이즈(noise)를 매 스텝(step, $t$)마다 추가한 후 다시 제거하는 과정을 학습하면서 데이터를 생성하는 deep generative model입니다.

Diffusion model은 크게 2가지 단계로 구성됩니다.
1️⃣ Forward process(diffusion process)
입력 데이터($x_0$)로부터 노이즈(noise; $\epsilon \sim N(\mu, \sigma^2)$)를 조금씩 더해가면서 입력 데이터($x_0$)는 완전한 noise 이미지($x_T$)가 생성됩니다.

⭐ 정규분포의 모수인 $\mu, \sigma^2$은 고정되어 있습니다. 즉, 고정된(fixed) 정규 분포로부터 샘플링 된 noise $\epsilon$를 매 step $t$ 마다 더해줍니다.
2️⃣ Reverse process(Diffusion model의 학습 부분)
완전히 noise된 이미지($x_T$)에서부터 노이즈(noise; $\epsilon~ \sim N(\mu', \sigma^{'2}$)를 조금씩 제거해가면서 원본 이미지($x_0$)로 복원해가는 과정입니다.
⭐ forward process에서 매 step $t$마다 추가된 noise를 reverse process에서 예측하여 제거하면 원본 이미지($x_0$)로 복원이 가능합니다. 따라서, 우리는 각 step별 $\epsilon$ 혹은 모수 $\mu', \sigma^{'2}$을 추정해야 합니다. ( → Diffsuion model의 학습 단계 )
즉, $t$ 시점의 이미지를 입력으로 받아 각 픽셀별로 추가된 noise를 예측하는 것입니다.
Diffusion model의 학습이 이루어지는 전체적인 architecture은 다음과 같습니다.
우리는 각 step $t$의 noisy image의 노이즈(noisy, $\epsilon$)을 예측해야 합니다.
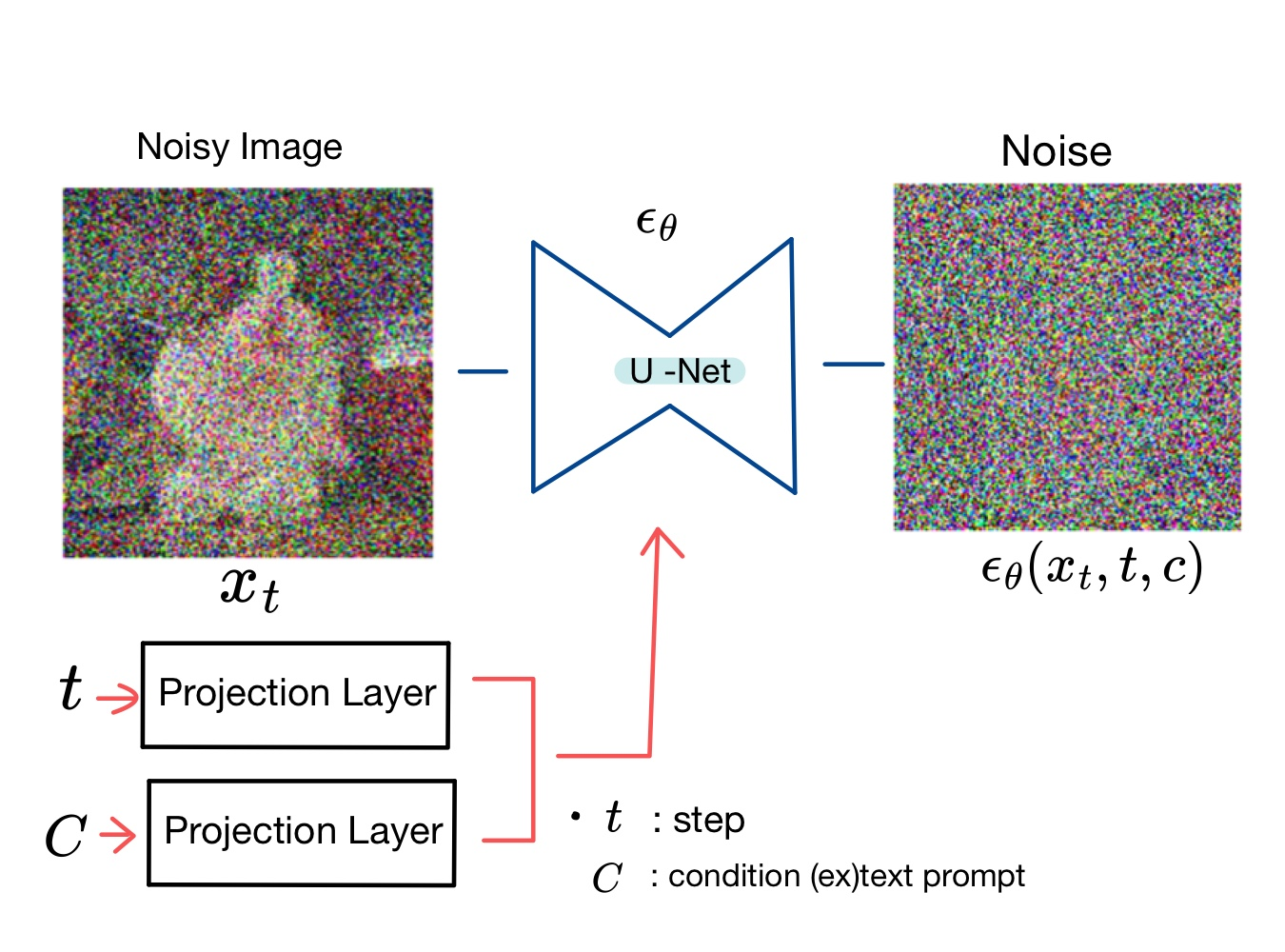
Noisy image $x_t$ 에 별도로 몇 번째 step $t$인지에 대한 값과 추가적인 조건 $c$ (ex. 생성할 이미지를 표현하는 text 정보)이 존재하는 경우 입력받아 $t$ 번째 step의 noise를 예측합니다.
※ 참고
대표적으로 text-to-image(T2I) 모델인 stable diffusion model은 추가적인 조건 $c$로 생성할 이미지를 표현하는 text prompt를 입력받아 이미지를 생성합니다.
Diffusion model은 보통 noise를 예측하는 모델 $\epsilon_{\theta}$로 U-Net을 사용합니다.
U-Net은 입력 이미지(input)와 동일한 resolution(해상도)의 output을 내기에 적절한 구조를 갖고 있습니다.
본 글에서는 diffusion model의 기본적인 과정에 대해 알아보았습니다.
Diffiusion model의 자세한 설명은 다음 글에서 논문 DDPM(2020)와 함께 살펴보겠습니다.