▶ 개요
Computer vision에는 크게 4가지의 task가 존재합니다.
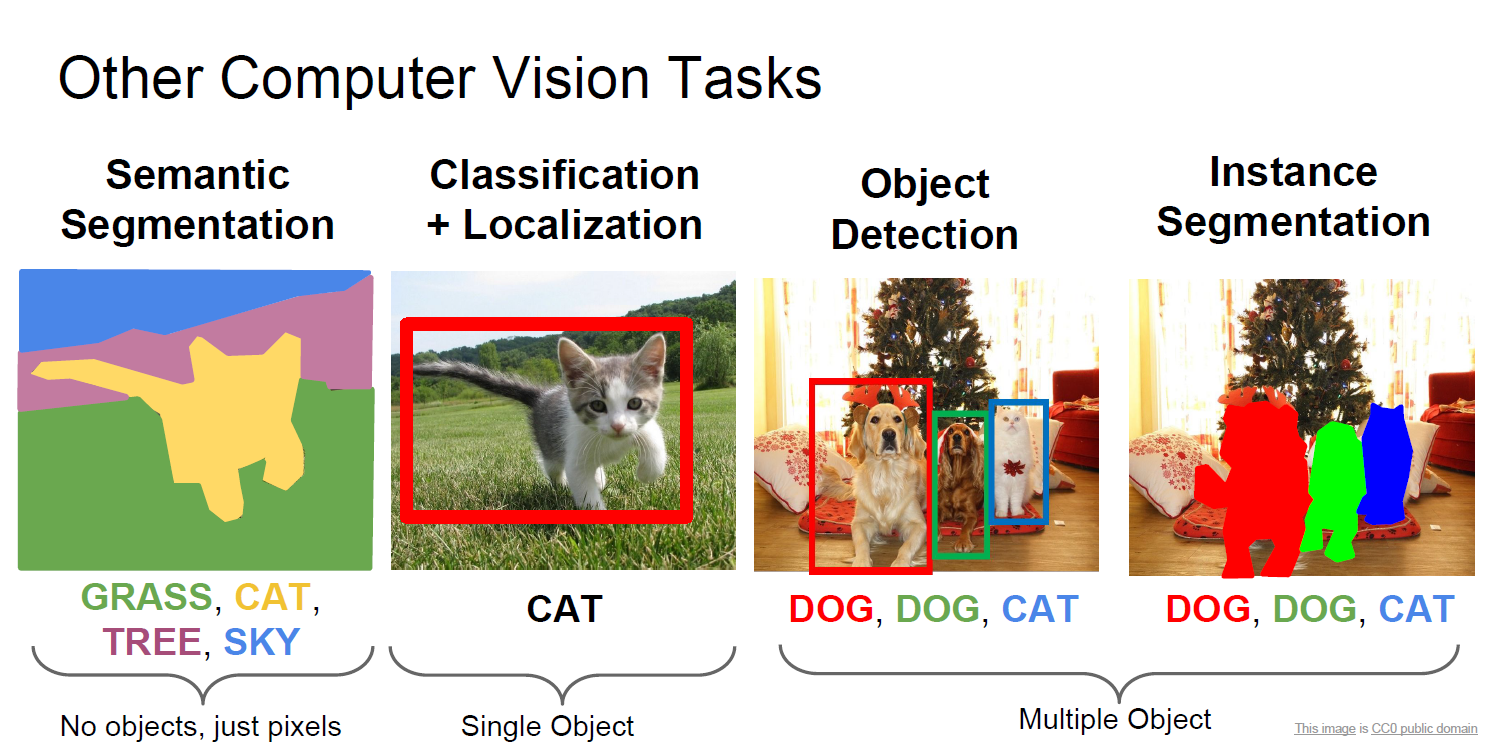
1. Semantic Segmentation
- 이미지 안의 모든 픽셀(pixel)들에 대해서 classification(or categorize)을 합니다.
- (예시) [Figure 1]에서의 'senmantic segmentation'은 각 픽셀이 GRASS, CAT, TREE, SKY인지를 결정하는 픽셀 분류 문제입니다.
2. Classification (+ Localization)
- 하나의 이미지에 대한 label 예측(→ classification)뿐만 아니라 이미지 내에 하나의 object(→ Single object)에 대해 bounding box(bbox)로 위치( → localization)도 나타냅니다.
- (예시) [Figure 1]에서의 'classification + localization'은 고양이 이미지에 대해서 CAT으로 예측함과 동시에 CAT의 위치를 bbox로 표시하였습니다.
3. Object detection(객체 인식)
- 이미지 내에 여러 개의 객체(→ multiple object)의 존재와 위치를 bounding box(bbox)로 나타냄과 동시에 각 bbox에 해당하는 객체의 클래스를 예측하는 task입니다.
- '(Senmantic / Instance) Segmentaion'과의 차이점
- Object detection은 위치 기반으로 객체를 탐지하는 반면, Segmentation은 픽셀을 기준으로 객체를 식별합니다.
- (예시) [Figure 1]에서의 'Object detection'은 3개의 객체(DOG, DOG, CAT)에 대해서 bbox를 예측함과 동시에 각 bbox에 해당하는 객체의 클래스도 식별하였습니다.
4. Instance Segmentation
- 이미지 내에 여러 개의 객체(→ multiple object)의 픽셀(pixel)을 분할하여 각 객체를 식별하고 각 객체에 대한 클래스를 예측합니다.
- Segmentation은 크게 'Senmantic Segmentation'과 'Instance Segmentation'으로 분류할 수 있으며 2개의 차이점은 다음과 같습니다.
- Senmantic Segmentation은 픽세들이 각 클래스에 대해 포함 여부를 확인합니다( → 클래스에 포함되면 $1$, 아니면 $0$). 따라서, 같은 클래스에 속하는 객체끼리는 서로 구분이 불가능합니다.
- 반면, instance segmentation은 각 pixel별로 각 클래스별 포함 여부를 확인하는 것이 아닌 객체가 존재하는지 여부를 계산합니다. 또한, 두 객체가 같은 클래스에 속하더라도 구별이 가능합니다.
- (예시) [Figure 1]에서의 'Instance Segmentation'은 3개의 객체( DOG, DOG, CAT )에 대해서 픽셀을 기준으로 객체를 식별함과 동시에 각 객체별 클래스도 예측하였습니다.
본 글은 computer vision의 주요한 4가지 task에 대한 개요를 살펴보았습니다.
추후에 Object Detection과 Semantic/Instance Segmentation에 대해서 자세하게 살펴보고자 합니다.
'Deep Learning > Convolution Neural Network' 카테고리의 다른 글
| Semantic Segmentation (1): Sliding Window (0) | 2024.03.20 |
|---|---|
| LeNet-5 (0) | 2024.03.19 |
| Convolution Layer 개요 (0) | 2024.03.18 |


