본 글은 2018년에 발표된 Deep One Class Classification 논문을 바탕으로 작성하였습니다.
One Class Classification(OCC)란, 데이터 불균형이 극심한 상황에서 정상 데이터에 대한 분류 경계면을 생성함으로써 비정상 데이터를 탐지하는 방법론입니다.
OCC의 초창기(classical) 방법론은 One Class SVM 혹은 Kernel Density Estimation 등이 존재합니다. 두 방법론 모두 커널 기반 방법론으로 두 가지 큰 단점이 존재합니다.
- bad computational scalability(→ 비싼 계산 비용)
- the curse of dimensionality( → 차원의 저주)
- 차원의 저주란, 데이터 학습을 위해 차원이 증가하면서 학습 데이터 수가 차원의 수보다 적어져 성능이 저하되는 현상을 지칭합니다.
Deep Support Vector Data Description(Deep SVDD)는 커널(kernel) 기반 one-class classification 중 Support Vector Data Description(SVDD)를 바탕으로 생성된 모델이며 계산 비용이 큰 커널(kernel) 대신 인공신경망(neural network)을 사용하였습니다.
1. Kernel-based One-Class Classification
1.1 One Class Support Vector Machine(OC-SVM)
One Class SVM의 목적은 feature space 상에서 원점으로부터 데이터를 가장 잘 분류하는 초평면(hyper-plane $w$)를 찾는 것이 목적입니다. One Class SVM의 목적함수(objective function or primal problem)는 식 $(1)$과 같습니다.
- Given Dataset: $ \mathbf{X} = \{x_1, x_2, \cdots, x_n \}$ with $x_i \in \mathbb{R}^n$
$$\min_{w, \rho, \xi} \dfrac{1}{2}||w||^2_2 -\rho + \dfrac{1}{\nu n} \sum^n_{i=1} \xi_i
\\
\text{ s.t. } w^T\phi_k(x_i) \geq \rho - \xi_i, \, \xi_i \geq 0, {}^\forall {i} \tag{1}$$
- $\rho$: 원점에서 초평면(hyper-plane) $w$까지의 거리
- $\xi_i = \max(0, \rho - w^t \phi(x_i)) \geq 0$
- $\nu \in (0,1]$
▶ First Term(→ Regularization Term) : $\dfrac{1}{2}||w||^2_2$
초평면 $w$를 찾는 과정에서 학습 데이터에 과적합 방지를 위한 식입니다.
▶ Second Term: $-\rho$
원점과 초평면 $w$와의 거리로 두 거리를 최대화하는 $\rho$를 찾는 것이 목적입니다.
▶ Third Term(→ Penalty Term) : $\dfrac{1}{\nu n} \sum^n_{i=1} \xi_i $
One Class SVM은 soft-boundary로 마진(margin)에 데이터가 존재하는 것을 허용합니다. 즉, $w^T \phi(x_i) < 0$ 영역에 일부 데이터를 허용합니다. 다만 너무 많은 오분류된 데이터를 허용하면 안되기 때문에 $\xi_i$를 이용하여 패널티를 부여합니다.
- $w^T\phi(x_i) \geq \rho$인 경우, $\xi_i = 0$
- $w^T\phi(x_i) < \rho$인 경우, $\xi_i > 0$
[$\nu$-property]
$\nu \in (0,1]$는 $w^T \phi(x_i) - \rho \leq 0$ 영역에 존재하는 객체(→ support vector)의 수의 비율의 하한값(lower bound)이자 패널티를 부여받는 서포트 벡터의 수( $w^T \phi(x_i) - \rho < 0$ 영역에 존재하는 객체 )의 상한값(upper bound)입니다.
보통 훈련 데이터에 존재하는 이상치 비중에 대한 사전 지식을 통해 $\nu$ 값을 설정해 줍니다.
원점으로부터 데이터를 가장 잘 분류하는 초평면 $w$를 찾는 식과 패널티 식과의 trade-off 관계는 하이퍼-파라미터 $\nu \in (0,1]$를 통해 조정됩니다.
- $\nu$ 값을 높게 설정할수록 $w^T \phi(x_i) - < \leq 0$ 영역에 왠만해서는 데이터를 허용하지 않다는 것을 의미하기 때문에 복잡한 분류 경계면이 생성됩니다.
- $\nu$ 값을 낮게 설정할수록 $w^T \phi(x_i) - < \leq 0$ 영역에 존재하는 데이터에 가중치를 주기보다는 원점으로부터 정상 데이터를 가장 잘 분류하는 초평면 $w$를 찾는데 집중하겠다는 것을 의미합니다.
1.2 Support Vector Data Description(SVDD)
Support Vector Data Description(SVDD)의 목적은 정상 데이터에 대한 분류 경계면을 초평면(hyper-plane)이 아닌 중심이 $c$, 반지름이 $R$인 초구(hyper-sphere)를 찾는 것입니다. SVDD의 목적함수(objective function or primal problem)는 식 $(2)$와 같습니다.
$$\min_{R,c,\mathbf{\xi}} R^2 + \dfrac{1}{\nu n} \sum_i \xi_i \\ \text{s.t.} || \phi_k(x_i) - c||^2_{F_k} \leq R^2 + \xi_i, \, \xi_i \geq 0, \forall{i} \tag{2}$$
- $R \in \mathbb{R}$: 초구(hyper-sphere)의 반지름
- $c \in \mathbb{R}^n$: 초구(hyper-sphere)의 중심
- $\xi_i = \max (0, ||\phi(x_i) - c||^2 - R^2)$
▶ First Term: $R^2$
초구의 반지름을 최소화하는 식으로 가장 작은 초구를 찾는 식입니다.
▶ Second Term (→ Penalty Term) : $\dfrac{1}{\nu n} \sum_i \xi_i$
Deep SVDD는 soft-boundary로 초구(hyper-sphere) 밖에 존재하는 데이터를 허용합니다. 즉, $|| w^T\phi(x_i) - c||^2 - R^2 > 0$ 영역에 일부 데이터를 허용합니다. 다만 너무 많은 오분류된 데이터를 허용하면 안되기 때문에 $\xi_i$를 이용하여 패널티를 부여합니다.
- $|| w^T \phi(x_i) - c||^2 \leq R^2$인 경우, $\xi_i = 0$
- $ || w^T \phi(x_i) - c||^2 > R^2 $인 경우, $\xi_i > 0$
[$\nu$-property]
$\nu \in (0,1]$는 $|| w^T \phi(x_i) - c||^2 - R^2 \geq 0$ 영역에 존재하는 객체(→ support vector)의 수의 비율의 하한값(lower bound)이자 패널티를 부여받는 서포트 벡터의 수( $|| w^T \phi(x_i) - c||^2 - R^2 > 0$ 영역에 존재하는 객체 )의 상한값(upper bound)입니다.
마찬가지로 보통 훈련 데이터에 존재하는 이상치 비중에 대한 사전 지식을 통해 $\nu$ 값을 설정해 줍니다.
정상 데이터를 포함하는 가장 작은 초구를 찾는 식과 패널티 식과의 trade-off 관계는 하이퍼-파라미터 $\nu \in (0,1]$를 통해 조정됩니다.
- $\nu$ 값을 높게 설정할수록 $|| w^T \phi(x_i) - c||^2 - R^2 > 0$ 영역에 왠만해서는 데이터를 허용하지 않다는 것을 의미하기 때문에 복잡한 분류 경계면이 생성됩니다.
- $\nu$ 값을 낮게 설정할수록 $|| w^T \phi(x_i) - c||^2 - R^2 > 0$ 영역에 존재하는 데이터에 가중치를 주기보다는 정상 데이터를 최대한 포함하는 가장 작은 초구(hyper-sphere)를 찾는데 집중하겠다는 것을 의미합니다.
[One Class SVM과 SVDD의 단점]
두 방법론 모두 커널 기반 방법론으로 커널 함수를 통해 저차원 상의 데이터를 고차원으로 매핑합니다. 커널 함수는 보통 가우시안 커널(식 $(3)$)이 주로 사용됩니다.
$$K_{\theta}(x_i,x_j) = exp(- \dfrac{||x_i - x_j||^2}{2 \sigma^2}) \tag{3}$$
커널 함수의 경우, 데이터의 크기가 커질수록 커널 행렬의 크기의 제곱에 비례하여 빠르게 증가합니다. 즉, 시간과 메모리 비용이 크며 고차원 데이터에서 정상 데이터가 갖고 있는 특징을 추출하기 어렵다는 단점이 존재합니다.
One Class SVM 및 SVDD에 대한 보다 더 자세한 설명은 아래 블로그를 참조하시를 바랍니다.
One-Class SVM
1. One-Class Classification One Class Classification(OCC)란, 정상 데이터와 이상 데이터 사이에 불균형이 존재할 때 정상 데이터를 정의하는 경계면을 정의하여 이상 데이터를 탐지하는 기법이다. One-Class SVM
iy322.tistory.com
Support Vector Data Description(SVDD)
1. Support Vector Data Description(SVDD) 1.1 Definition SVDD는 One-Class SVM과 관련된 기술이다. SVDD는 분류 경계면(hyperplane)을 찾는 것 대신에 정상데이터를 최대한 많이 포함하는 가장 작은 초구(hypersphere)를 찾
iy322.tistory.com
2. Deep SVDD
Deep SVDD는 커널 함수 $K(\cdot, \cdot)$ 대신 인공신망(neural network) $\phi(\cdot;W)$를 사용하여 정상 데이터의 feature representation을 학습하여 정상 데이터에 대한 분류경계면(초구)를 생성합니다.
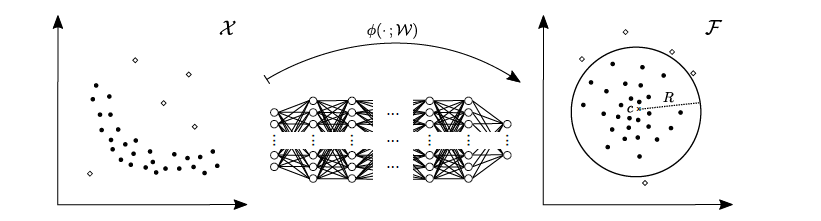
2.1 Soft-boundary Deep SVDD
▶ Notation
- Given Dataset: $D_n= \{x_1,x_2, \cdots, x_n\}, \, x_i \in \mathbb{R}^d$
- $\mathbf{\chi}$: Input Space
- $\mathbf{\digamma}$: output Space
- Neural Network $\phi(\cdot ; W): \mathbb{R}^d \to \mathbb{R}^q$
- $W = \{W^1, W^2, \cdots, W^L\}$
- $L$개의 hidden layer
- $\phi(x;W) \in F$: parameter $W$를 갖는 neural network $\phi(\cdot)$를 통해 산출된 $x \in \mathbf{X}$의 feature representation vector입니다.
▶ Objective Function
Deep SVDD는 output space $\mathbf{\digamma}$ 상에서 중심이 $c \in \mathbf{\digamma}$, 반지름이 $R>0$인 가장 작은 초구를 찾는 것과 정상 데이터의 특성을 추출하는 network parameter $W$를 결합하여(jointly) 학습합니다.
Deep SVDD의 목적 함수는 식 $(4)$와 같습니다.
$$\min_{R,w} R^2 + \dfrac{1}{\nu n} \sum^n_{i=1} \max \{0, ||\phi(x_i;W) - c||^2 - R^2 \} + \dfrac{\lambda}{2} \sum^L_{l=1} ||W^l||^2_2 \tag{4}$$
▷ First Term: $R^2$
초구의 반지름을 최소화하는 식으로 가장 작은 초구를 찾는 식입니다.
▷ Second Term (→ Penalty Term) : $xi_i = \max \{0, ||\phi(x_i;W) - c||^2 - R^2 \}$
Soft boundary Deep SVDD는 초구(hyper-sphere) 밖에 존재하는 데이터를 허용합니다. 즉, $||\phi(x_i;W) - c||^2 - R^2 > 0$ 영역에 일부 데이터를 허용합니다. 다만 너무 많은 오분류된 데이터를 허용하면 안되기 때문에 $\xi_i$를 이용하여 패널티를 부여합니다.
- $||\phi(x_i;W) - c||^2 < R^2$인 경우, 초구 안에 존재하는 데이터로 $\xi_i = 0$ 입니다.
- $||\phi(x_i;W) - c||^2 = R^2$인 경우, 초구 경계선 위에 존재하는 데이터로 $\xi_i = 0$입니다.
- $||\phi(x_i;W) - c||^2 > R^2$인 경우, 초구 밖에 존재하는 데이터로 $\xi_i > 0$입니다.
[$\nu$-property]
Soft boundary Deep SVDD에서도 $\nu$-property는 성립합니다.
$\nu \in (0,1]$는 $||\phi(x_i;W) - c||^2 - R^2 \geq 0$ 영역에 존재하는 객체(→ support vector)의 수의 비율의 하한값(lower bound)이자 패널티를 부여받는 서포트 벡터의 수( $||\phi(x_i;W) - c||^2 - R^2 > 0$ 영역에 존재하는 객체 )의 상한값(upper bound)입니다.
마찬가지로 보통 훈련 데이터에 존재하는 이상치 비중에 대한 사전 지식을 통해 $\nu$ 값을 설정해 줍니다.
정상 데이터를 포함하는 가장 작은 초구를 찾는 식과 패널티 식과의 trade-off 관계는 하이퍼-파라미터 $\nu \in (0,1]$를 통해 조정됩니다.
- $\nu$ 값을 높게 설정할수록 $||\phi(x_i;W) - c||^2 - R^2 > 0$ 영역에 왠만해서는 데이터를 허용하지 않다는 것을 의미하기 때문에 복잡한 분류 경계면이 생성됩니다.
- $\nu$ 값을 낮게 설정할수록 $||\phi(x_i;W) - c||^2 - R^2 > 0$ 영역에 존재하는 데이터에 가중치를 주기보다는 정상 데이터를 최대한 포함하는 가장 작은 초구(hyper-sphere)를 찾는데 집중하겠다는 것을 의미합니다.
▷ Third Term (→ RegularizationTerm) : $\dfrac{\lambda}{2} \sum^L_{l=1} ||W^l||^2_2 $
정상 데이터가 초구의 중심 $c$에 가깝게 매핑되도록 파라미터 $W$를 학습합니다. 이와 같은 최적화 과정이 제대로 이루어지기 위해서는 정상 데이터가 갖고 있는 공통 요인(혹은 특성)을 잘 추출해야 합니다.
학습 과정에서 $W$가 훈련 데이터에 대해 과적합(over-fitting) 되는 것을 방지하기 위해 regularization term이 필요합니다.
- $\lambda \in (0,1)$: weight decay
만약, 정상 데이터가 갖고 있는 공통 요인을 잘 추출하여 정상 데이터가 초구의 중심 $c$에 가깝게 매핑되도록 $W$를 잘 학습하였다면, 추론 단계에서 정상 데이터는 중심 $c$에 가깝게 매핑되고 비정상 데이터는 초구 밖에 매핑될 것입니다.
▶ Anomaly Score
$$s(x) = s(x) = || \phi(x;W^*) - c||^2 - R^{*2}$$
- network parameters of a trained model: $W^*,R^*$
- $\hat{y} = \begin{cases} 1 &\text{if } s(x) > 0 \\ 0 &\text{if } s(x) \leq 0 \end{cases}$
- $s(x) > 0$인 경우는 초구 밖에 존재하는 객체이므로 비정상 객체(→ label=1)로 판단합니다.
- $s(x) \leq 0$인 경우는 초구 안 혹은 경계선에 존재하는 객체이므로 정상 객체(→ label=0)로 판단합니다.
2.2 One Class Deep SVDD
One Class Classification(OCC)에서는 대부분의 훈련 데이터는 정상 데이터로 이루어져 있다고 가정하기 때문에 목적함수(objective function)를 식 $(4)$를 식 $(5)$와 같이 단순화할 수 있습니다.
$$\min_{W} \dfrac{1}{n} \sum^n_{i=1} || \phi(x_i;W) - c||^2 + \dfrac{\lambda}{2} \sum^L_{l=1} ||W||^2_2 \tag{5}$$
▷ First Term: $ \dfrac{1}{n} \sum^n_{i=1} || \phi(x_i;W) - c||^2 $
Quadratic loss를 사용해 Soft boundary Deep SVDD와는 다르게 모든 객체의 feature representation(→ $\phi(x_i;W), {}^{\forall} i$)이 중심 $c$에 가깝게 매핑되도록 학습함으로써 직접 초구의 반경을 축소시킵니다.
▷ Second Term: $ \dfrac{\lambda}{2} \sum^L_{l=1} ||W||^2_2 $
학습 과정에서 $W$가 훈련 데이터에 대해 과적합(over-fitting) 되는 것을 방지하기 위해 regularization term이 필요합니다.
▶ Soft Boundary Deep SVDD v.s. One Class Deep SVDD
Soft Boundary Deep SVDD는 초구 밖에 데이터가 존재하는 것을 허용하면서 초구 밖에 존재하는 데이터에 한해서만 패널티를 부여합니다.
반면, One Class Deep SVDD는 초구 밖에 데이터가 존재하는 것을 허용하면서 모든 데이터에 대해서 패널티를 부여합니다. 즉, 모든 데이터가 중심 $c$에 가깝게 매핑되도록 직접 축소함으로써 정상 데이터의 분류 경계면을 생성합니다.
▶ Anomaly Score
$$s(x) = s(x) = || \phi(x;W^*) - c||^2$$
- network parameters of a trained model: $W^*$