본 내용은 Self Supervised Learning(SSL) 방법론에 대한 글입니다.
1. Self-Supervised Learning(SSL)
※ Self-Supervised Learning(SSL)의 참고자료
▶ Self-Supervised Learning(SSL)이란?
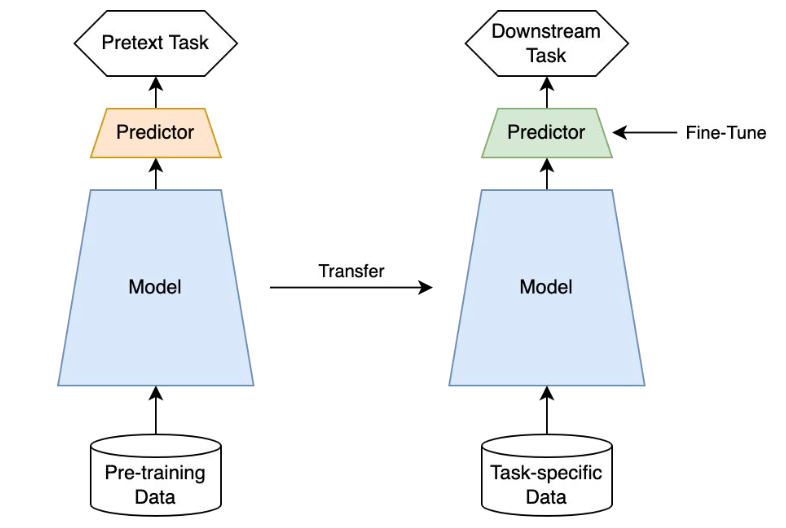
Self-Supervised Learning은 representation learning의 일종으로 unlabeled dataset으로부터 좋은 data representation을 얻는 것을 목표로 합니다.
▶ 등장배경
[1]. Supervised Learning을 위한 data labeling의 비용은 비쌉니다. 특히, high quality의 labeled data를 얻는 것은 어렵습니다.
[2]. 만약, 데이터를 잘 표현하는 representation vector를 (사전) 학습한다면, 이는 downstream tasks에 쉽게 transfer(적용) 시킬 수 있으며 더 나아가서는 supervised learning보다 더 좋은 성능을 낼 수 있습니다.
[1]과 [2]를 배경으로 SSL의 다양한 방법론들이 제안되었습니다.
▶ Pretext Tasks
SSL은 Pretext Task(일부러 어떤 구실을 만들어서 푸는 문제)라고도 불립니다.
▶ Methodology
SSL의 방법론은 크게 Self-prediction과 Contrastive Learning으로 구성되어 있습니다.
[1]. Self-prediction

- Given an individual data sample, the task is to predict one part of the sample given the other part
- 개별 샘플 내에서 데이터의 일부를 이용해(W1 dataset), 나머지 데이터(W2 dataset)을 예측하는 태스크
[2]. Contastive Learning

- Given multi data samples, the task is to predict the relationship among them.
- Batch 내의 data sample들 사이의 관계를 예측하는 태스크
- 두 샘플간의 관계를 학습하는 방식
2. SSL Methodology [1]: Prediction Task
" " "
to predict a part of data from the rest while pretending we don't know that part
" " "
Prediction Task의 경우 일부 과거 데이터를 기반으로 다음 시점을 예측하는 시계열 예측 문제와 유사합니다.

Prediction Task는 [Figure 3]와 같이 일부 데이터를 가지고 특정 부분을 예측함으로써 representation vector를 학습합니다.
▶ Methodology
Prediction Task의 대표적인 방법론으로 크게 다음과 같이 4가지로 구분할 수 있습니다.
- Autoregressive(AR) generation
- Masked generation
- Innate relationship prediction
- Hybrid self-prediction
[1]. Self Prediction: Autoregressive(AR) generation

순서가 있는 데이터(sequential data)가 주어진 경우,
과거 데이터를 기반으로 미래 시점을 예측함으로써 representation vector를 학습합니다.
관련 모델로는 Audio(WaveNet, WaveRNN) / Autoregressive language model(GPT, XLNet) / Images in raster scan(PixelCNN, PixelRNN, iGPT)가 존재합니다.
[2]. Self Prediction: Masked Generation

데이터의 일부분을 랜덤하게 마스킹(masking)합니다. 마스킹되지 않은 부분(unmasked information)을 통해 masking 영역(missing 영역)을 예측함으로써 representation vector를 학습합니다.
관련 모델로는 Masked Language Modeling(BERT), Images with maksed patch(denoising autoencoder, context autoencoder, colorization)이 존재합니다.
[3]. Self-Prediction: Innate Relationship Prediction
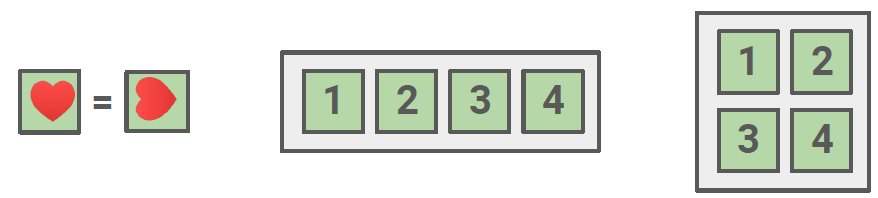
데이터 샘플의 변형(ex. segmentation, rotation)을 해도 데이터의 본질적인 정보는 동일할 것이라는 전제 하에 어떤 변형(augmentation)이 사용되었는지를 예측하는 태스크입니다.
관련 모델로는 Order of Image patches, Image rotation, Counting Features across patches 등이 존재합니다.
[4]. Self-Prediction: Hybrid Self-prediction Models
앞의 방법론들을 결합해서 사용한 모델입니다.

관련 모델로는 VQ-VAE+AR 과 VQ-VAE + AR + Adversarial이 존재합니다.
3. SSL Methodology [2]: Contrastive Learning
Contrastive Learning은 data sample간의 관계를 학습한다고 언급했습니다.
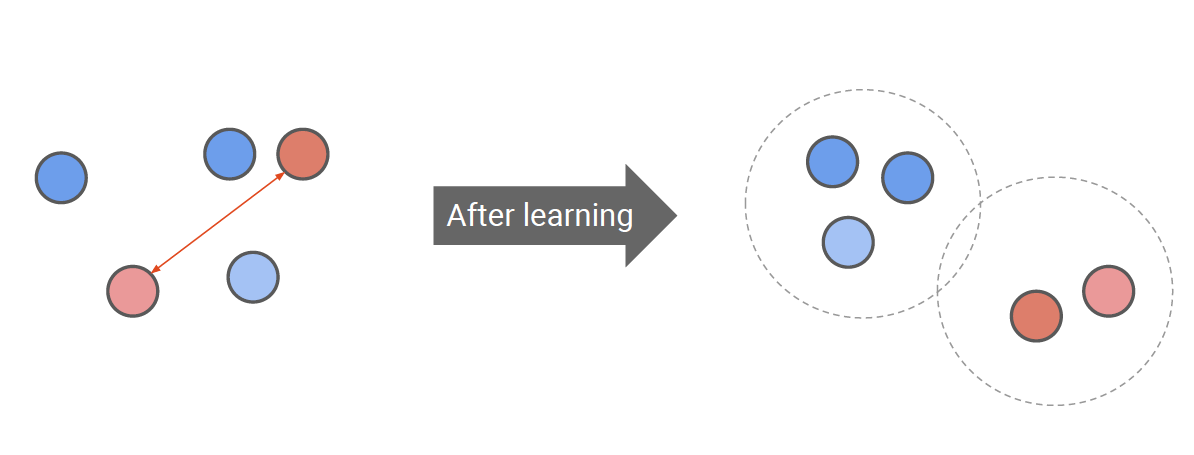
Contrastive Learning은 [Figure 8]과 같이 임베딩 공간(embedding space) 상에서 비슷한 속성을 가진 객체끼리는 서로 가깝게, 다른 속성을 가진 객체끼리는 서로 멀리 위치하도록 학습합니다. Contrastive Learning에서는 주요한 4가지 개념이 존재합니다.
- Anchor: 현재 기준이 되는 데이터 샘플(query라고도 함)
- Positive pair: 기준이 되는 데이터 샘플과 같은 class를 가지는 상관관계가 높은 데이터 샘플(key)
- Views: anchor와 같은 semantic을 가지는 데이터 샘플(positive sample).
- Negative pair: 기준이 되는 데이터 샘플과 다른 class를 가지는 상관관계가 낮은 데이터 샘플.

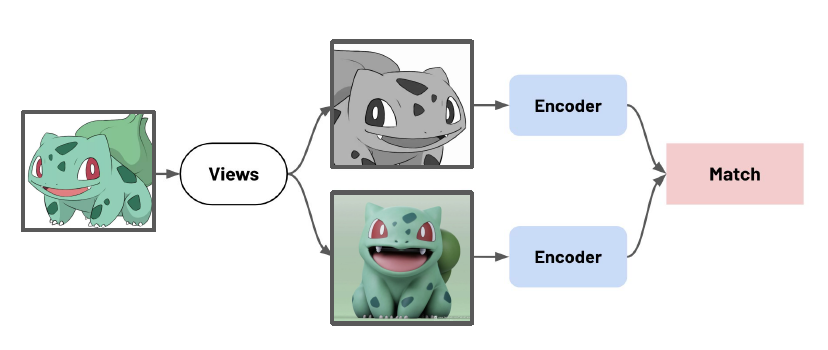
[Figure 9]를 통해서도 알 수 있듯이
Contrastive Learning은 positive pairs간의 거리는 가깝게 negative pairs간의 거리는 멀게 학습을 합니다. 그리고 유사한지, 유사하지 않은지에 기준이 되는 현재 data point가 anchor입니다.
Contrastive Learning에는 Inter-sample classification / Feature Clustering / Non-contrastive methods가 존재합니다.
Why? Negative sample은 왜 필요한가?
만약, positive pair만 사용할 경우, 네트워크 입장에서 계속 같은 class에 속하는 객체끼리만 embedding vector를 가깝게 학습하기 때문에 결국, 어떤 객체가 입력되도 동일한 representation vector(constant vector)를 출력하는 collasped problem이 발생합니다. 따라서, contrastive learning에서 collapsed problem을 피하기 위해서는 negative sample이 필요합니다.
Problem of Contrastive Learning
Negative sample이 사용되기 때문에 큰 배치 사이즈가 필요하여 메모리 비용이 크며 data augmentation 방법에 따라 성능이 달라진다는 단점이 존재합니다.
이를 보완한 방법이 non-contrastive method입니다.
Non-contrastive method에 대한 자세한 내용은 다음 글에서 non-contrastive method 중 Boostrap Your Own Latent(BYOL)으로 살펴보겠습니다.
'Deep Learning > Self Supervised Learning' 카테고리의 다른 글
| Boostrap Your Own Latent(BYOL) (1) | 2024.06.02 |
|---|
