Graph Convolutional Neural Networks(GCNNs)와 Bayesian Neural Networks(BNN)을 모두 적용한 Bayesian Graph Convolutional Neural Networks에 대해 담은 논문에 대해 정리해 보고자 한다. 이번에도 예제 이전까지에 대한 내용을 정리하고자 한다.
1. Introduction
최근에, convolutional neural network를 graph structure data에 적용하려는 다양한 시도를 통해 수 많은 발전과 향상이 있었다. GCN의 목적은 node들 사이의 관계를 나타내는 Ground Truth를 구하는 것이 목적이다. graph를 설계할 때, noisy data를 사용하거나 모델을 가정해서 사용하는 경우 성능에 안 좋은 영향을 끼친다. 즉 GCN의 한계점은 graph structure에 대한 uncertainty를 다루지 못 한다는 것이다. 비논리적인 edge가 포함되어 있을지도 모르고 혹은 매우 중요한 관계를 가지고 있는 특정 두 노드 사이에 엣지가 없는 경우가 존재한다. 따라서, uncertainty를 고려하는 model이 필요하다.
이 논문에서는, bayesian approach를 채택해 parameteric family of random graphs를 생성하는 것이다. 그리고, random graph parameters와 node(or graph) lables의 결합 사후분포를 추론하는 것을 목표로 한다. 즉, 모수적인 분포를 사용해 random graph를 형성하며 assortative mixed membership stochastic block model을 사용할 것이다. 비록 계산이 오래 걸리지만, 더 적은 데이터로 학습이 가능하며 uncertainty를 구하는데 더 좋은 성능을 낸다. 또한, noise나 adversarial attack으로부터 robustness를 더 잘 보인다.
2. Background
이전 블로그에서 GCN이랑 BNN에 대해 다루었다. 하지만, 이 논문에서 BGCN에 대해 다루기 전 배경 지식으로 GCN과 BNN을 필요로 해 내용이 서술되어 있어 간단하게 정리 해보고자 한다.
Bayesian Neural Network
[Lab Presentation #1] - Bayesian Neural Network
iy322.tistory.com
Graph Convolutional Network
[Deep Learning] Graph Convolution Network(GCN)
1. CNN 간략하게 설명 Convolution이란? Convolution Filter(kernel)를 이용하여 image를 순회하는 dot product를 계산하고, 기존의 데이터로부터 filter를 이용하여 새로운 tensor(=activation map)을 만드는 것...
iy322.tistory.com
2.1 Graph Convolutional Neural Networks(GCNNs)

graph는 N개의 node 집합 V와 edge E로 이루어져 있다고 가정한다. 각각의 노드는 feature x에 대한 정보가 담겨져 있다. 우리가 하고자 하는 것은 feature x와 observed graph structure를 이용해 unlabelled node의 label를 예측하는 것이다. GCN은 neural network 구조 안에서 graph convolution operations을 수행함으로써 위의 업무를 수행할 수 있다.

A : Adajency Matrix
(The Adajency Matrix is derived from the observed graph and determines how the output features are mixed across the graph at each year)
X : feature vectors as the rows of a matrix
W(l) : the weights of the neural network at layer l
H(l): the output features from layer l-1
sigma: a non-linear activation function
기호를 다시 정리하면 다음과 같다.

가중치 학습은 observed labels Y와 network predictions Z 사이의 error 혹은 loss 값이 최소화되도록 backpropgation algorithm을 통해 수행되어진다. 모델 성능은 skip connection, gates, attention을 사용함으로써 높일 수 있다.
2.2 Bayesian Neural Network
Neural Network에서 주어진 input, 그에 따른 output이 있을 때 그 관계를 나타내는 function을 찾는 것이 목표이다. function은 layer의 수, activation 종류 등을 의미한다. function의 경우, weight에 달려 있다. Bayesian에서는 weight가 random variable이다. Standard Neural Network와 Bayesian Neural Network의 가장 큰 차이점이다.
새로운 관측값 x에 대한 예측 식은 다음과 같다.


Classification Data 경우, 주로 likelihood로 softmax function을 사용한다.
Regression Data의 경우, 주로 likelihood로 Gaussian likelihood를 사용한다.
문제점은, Posterior Distribution은 계산하기 힘들다. 따라서, Posterior Distribuion을 varaince inference(변분추론), Markov Chain Monte Carlo 방법을 통해 추정한다.
요약해서 정리해보면 다음과 같다.

3. Methodology
observed graph를 통해 the joing posterior of the random graph parameter를 추정하는 것이 추론 목표다. 최종적인 목표는 label의 posterior distribution을 계산하는 것이다. label의 posterior distribution은 다음과 같다.
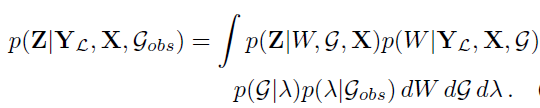
G: Graph
W: Weight
X: input data
lambda: the parameters that characterzie a family of random graphs.
Y: label
Z: target
우리는 위의 식을 계산하기 힘들고 불가능하다. 따라서, variational inference 혹은 MCMC 접근법을 사용할 것이다.

위의 식과 설명에 대해 다시 요약해서 설명해보면 다음과 같다.

Model a Graph : Assortative mixed membership stochastic block model
이 논문에서 가장 핵심이며 중요한 부분이라 생각한다. Graph를 만드는데 assortative mixed membership stochastic block model을 사용했다. stochastic block model에 대해 간단하게 설명하고 논문의 내용으로 넘어가고자 한다.
Stochastic Block Model(SBM)
Stochastic Block Model(SBM)은 특정 node끼리 community structure를 가지는 graph를 만들 수 있는 generative model이다.

즉, 각 node들이 서로 가까운 관계를 가지는 node들도 있고,서로 먼 관계를 가지는 node들이 있는데, 가까운 관계를 가지는 node끼리 community를 형성하는 구조를 반영할 수 있다. stocahstic block model로 잘 형상화된 그래프의 경우, 대부분의 node들은 K개의 community 중 하나에 속할 가능성이 아주 높다.
SBM의 알고리즘은 다음과 같다.

SBM을 사용하는 경우, community structure를 표현할 수 있는 가장 큰 장점이 있다. 예를 들어, i와 j가 같을 때, 즉 두 node가 같은 block(community)에 속할 때는 edge가 생길 확률을 높게 하고, i와 j가 다른 block에 속할 때는 edge가 생길 확률을 낮게 함으로써 같은 block 속 node들끼리는 잘 연결되고 다른 block 속 node들끼리는 연결의 빈도가 낮게 만드는 것이 가능하다.
이제, 논문의 내용으로 넘어가고자 한다.
Assortative Mixed Membership Stocahstic Block Model(Assortative MMSBM)은 강한 community structure를 가진 graph를 모델화하는데 좋은 방법이다. 우리는 graph를 modeling하기 위해 lambda(beta, pi)를 추정해야 한다.

즉, pi_hat과 beta_hat을 추정 후, random graph를 modeling한다. weight의 posterior distribution으로부터 w를 sampling하면 우리가 예측하고자 하는 label 값을 MC drop out을 통해 추정할 수 있다.
Posteriror inference for MMSBM
random graph이므로 node 간의 연결 여부, 즉 edge의 존재 여부도 확률분포로부터 sampling한다.

the parameter pi and beta의 joint posterior distribution은 다음과 같다.
결국엔, piand beta의 joint posterior distribution을 maxmizing하는 pi 와 beta를 추정해야 한다.

Expanded Mean Parameterisation
최종적으로 우리의 목적은 다음과 같다.

gradient 기반 update를 하는 경우, 다음 constraints를 만족시키는 것을 보장하지 못한다는 문제점이 존재한다.
논문에서는 해결책으로 Expected Mean Parameterisation을 제안했다. parameter beta와 pi 대신에 다른 parameter를 대신해서 사용한다.

4. Stochastic Optimization and mini-batch sampling
BGCN의 Algorithm

'Graph(Graph Neural Network)' 카테고리의 다른 글
| Scalable MCMC for Mixed Membership Stochastic Blockmodels (0) | 2022.11.21 |
|---|---|
| GCN - Image Classification (0) | 2022.11.03 |
| Semi-Supervised Classification With Graph Convolutional Networks (0) | 2022.09.19 |
| Graph Convolutional Networks for Text Classification (0) | 2022.09.18 |
| Semi-Supervised Classification With Graph Convolutional Neworks (0) | 2022.09.18 |



