본 글은 책 "Pattern Recognition and Machine Learning"을 바탕으로 Variational Inference(변분법)에 대해 작성한 글입니다.
▶ Assumption
True posterior distribution, 사후분포, $P(Z|X)$ 계산이 불가능한 경우라고 가정하고 출발하겠습니다.
- $Z$: stochastic variable
- $X$: observed variable
▶ Approximation Distribution
True posterior distribution $P(Z|X)$ 계산이 불가능하기 때문에 근사해서 구하고자 합니다. 이때 크게 두 가지 방법으로 구성할 수 있습니다.
- Stochastic approach
- 대표적인 방법론) Markov Chain Monte Carlo(MCMC): 임의성을 가지는(단, $N$이 무한대로 커지면 true posterior distribution으로 수렴하는) stochastic technique입니다.
- [장점] true posterior distribution로 정확하게 근사할 수 있습니다.
- [단점] 샘플링 방법이 계산적으로 까다롭습니다. 즉, 계산이 비효율적입니다.
- Deterministic approach
- 대표적인 방법론) Variational Inference or Variational Bayes
- [장점] 계산이 효율적입니다.
- [단점] 정확하게 true posterior distribution을 구할 수 없습니다.
Stochastic approach와 Deterministic approach의 장점/단점을 통해 두 방법론은 서로 상호보완적임을 알 수 있습니다.
본 글에서는 Deterministic approach 중 Variational Inference에 대해 살펴보겠습니다.
Variational Inference(VI)
▶ Definition
Variational Inference(VI,변분법)은 최적화 문제를 푸는 방법으로 functional의 최적화 방법 중 하나입니다.
Functional은 입력값이 함수, 산출값이 스칼라로 함수를 특정 값으로 매핑해주는 함수를 의미합니다. 이러한 방법들은 input function이 존재할 수 있는 모든 공간을 탐색해야 합니다.
※ Functional 참고자료
Functionals and functional derivatives
The calculus of variations is a field of mathematics that deals with the optimization of functions of functions, called functionals. This topic was not taught to me in my computer science education, but it lies at the foundation of a number of important co
mbernste.github.io
▶ Assumption
반면, VI는 탐색 공간에 특정한 제한을 둠으로써 계산이 불가능했던 true posterior distribution $P(Z|X)$를 계산 가능하게 만들어 줍니다.
▶ Example
탐색 공간에 특정한 제한을 두는 두 가지 예시를 들겠습니다.
- Ex1) 특정 함수의 형태로 제안
- 최적화를 수행할 때 함수의 공간을 이차 함수로 제한
- Ex2) 고정된 기저 함수의 선형 조합
- 고정된 기저 함수들의 선형 조합으로 구성된 함수들만 고려함으로써 최적화는 기저 함수의 계수만 변경하여 수행.
- 계산을 더 간단하게 하고 효율적으로 만듦.
▶ Factorized Assumption
본 글에서는 VI의 제한 사항으로 factorized assumption을 사용하겠습니다.
Factorized assumption이란, 복잡한 확률분포를 단순화하여 근사하는 방법입니다.
- ex) 전체 확률분포를 개별 변수의 곱으로 근사함으로써 계산을 단순화
지금까지 VI에 대한 간략한 설명을 하였습니다. 본격적으로 VI에 대해 수식과 함께 살펴보겠습니다.
"" How the concept of variational optimization can be applied to the inference problem? ""
▶ Notation
- $N$ independent, identically distributed data
- observed variable $\mathbf{X} = \{x_1,x_2,x_3,\cdots,x_N\}$
- $p(\mathbf{X})$: marginal distribution or likelihood function
- stochastic variable $\mathbf{Z} = \{z_1,z_2,z_3,\cdots,z_N\}$
- $\mathbf{Z}$ ~ prior distribution
- Joint distribution: $p(\mathbf{X}, \mathbf{Z})$
▶ Purpose
VI의 목적은 true posterior distribution $p(\mathbf{Z}|\mathbf{X})$의 approximation distribution $q(\mathbf{Z})$를 구하는 것입니다.
Log marginal distribution $\ln(p(\mathbf{X}))$는 식 $(1)$과 같이 분해(decomposition)가 가능합니다.
$$\ln(p(\mathbf{X})) = L(q)+ KL(q||p) \tag{1}$$
- $L(q) = \int q(\mathbf{Z}) \ln( \dfrac{p(\mathbf{X,Z})}{q(\mathbf{Z})})dZ$: Evidence Lower Bound(ELBO)
- $KL(q||p) = -\int q(\mathbf{Z}) \ln( \dfrac{p(\mathbf{Z}|\mathbf{X})}{q(\mathbf{Z})})dZ$: Kullback-leibler divergence(KL divergence)
▶Evidence Lower Bound(ELBO): $L(q)$
$L(q)$는 $\ln(q(\mathbf{Z}))$를 사용해서 $\ln{p(\mathbf{X})}$로 근사화하는 식입니다.
▶Kullback-leibler divergence(KL divergence): $KL(q||p)$
$KL(q||p)$는 approximation distribution $q(\mathbf{Z})$와 true posterior distribution $KL(q||p)$의 차이입니다.
만약 $q(\mathbf{Z}) = p(\mathbf{Z}|\mathbf{X})$이라면,
$KL(q||p)=0$입니다.
즉, $q(\mathbf{Z})$를 최적화하여 $L(q)$를 최대화함으로써 $\ln(p(\mathbf{X}))$에 근사화할 수 있습니다.
이는 $KL(q||p)$를 최소화하는 것과 상응합니다.
만약 탐색 공간에 제한을 두지 않으면,
$L(q)$가 최대화될 때는 $KL(q||p)=0$인 경우입니다. → $q(\mathbf{Z}) = p(\mathbf{Z}|\mathbf{X})$
하지만, 이와 같은 경우는 보통 연산이 불가능합니다.
따라서, 본 글에서는 $q(\mathbf{Z})$에 제한 사항을 줄 것입니다.
▶ Approximation distribution $q(\mathbf{Z})$에 대한 제한 사항
- tractable distribution(다루기 쉬운 분포, 단순한 분포)
- sufficiently rich and flexible distribution(true posterior distribution에 대한 좋은 근사치를 제공하기 위한 가정)
이와 같이 다루기 쉽고 유연한 분포를 사용하고자 factorized assumption을 사용할 것입니다.
▶ Factorized distribution
$\mathbf{Z}$의 요소를 $\mathbf{Z}_i, \, i=1,2,\cdots, M$으로 분할합니다.
$$q(\mathbf{Z}) = \Pi^M_{i=1} q_i(\mathbf{Z}_i)$$
- 각 요소 q_i(\mathbf{Z}_i)에는 어떠한 가정(혹은 제약사항)을 두지 않겠습니다.
- 우리가 VI를 하기 위해 사용하는 가정은 factorized assumption 단 하나입니다. → $q(\mathbf{Z}) = \Pi^M_{i=1} q_i(\mathbf{Z}_i)$
▶ Purpose
✅ Maximizing $L(q)$ ↔ Minimizing $KL(q||p)$하는 $q^*(\mathbf{Z})$를 찾는게 목적
$$\begin{align}
L(q) &= \int q(\mathbf{Z}) ln \dfrac{p(\mathbf{X},\mathbf{Z})}{p(\mathbf{Z})} d\mathbf{Z} \\
&= \int \Pi^M_{i=1} q_i [ln(p(\mathbf{X}, \mathbf{Z})) - \sum^M_{i=1} ln(q_i)]d\mathbf{Z} \\
&= \int q_j \left[ \int ln(p(\mathbf{X}, \mathbf{Z})) \Pi_{i\ne j}q_j d\mathbf{Z}_i \right] d\mathbf{Z}_j - \int q_j ln(q_j) d\mathbf{Z}_j + \text{const1}\\
&= \int q_j ln (\tilde{p}(\mathbf{X,Z}))d\mathbf{Z}_j - \int q_j ln(q_j) d\mathbf{Z}_j + \text{const1}
\end{align} \tag{2}$$
- $\text{const1} = \int \Pi_{i \ne j} q_i \sum_{i \ne j} ln(q_i)d\mathbf{Z}_i$
- $ln (\tilde{p}(\mathbf{X,Z})) = E_{i \ne j}(ln(p(\mathbf{X,Z}))) + \text{const2}$
- $E_{i \ne j}(ln(p(\mathbf{X,Z}))) = \int ln(p(\mathbf{X}, \mathbf{Z})) \Pi_{i\ne j}q_j d\mathbf{Z}_i $
- $q$ 분포에 대한 모든 $\mathbf{Z}_i, \, i=1,2,\cdots,M$의 기댓값
식 $(2)$는 식 $(3)$과 같이 쓸 수 있으며 이는 $q_j(\mathbf{Z}_j)$와 $\tilde{p}(\mathbf{X,Z})$ 사이의 negative KL divergence를 나타냅니다.
$$L(q) = \int q_j ln (\dfrac{\tilde{p}(\mathbf{X,Z})}{q_j})d\mathbf{Z}_j + \text{const1} \tag{3}$$
- maximize L(q) ↔ minimize KL divergence between $q_j(\mathbf{Z}_j)$ and $\tilde{p}(\mathbf{X,Z})$
▶ Optimal Minimum: $q^*_j(\mathbf{Z}_j)$
식 $(3)$을 통해 $q_j(\mathbf{Z}_j) = \tilde{p}(\mathbf{X}, \mathbf{Z})$일 때, optimal minimum이 발생함을 알 수 있습니다.
Optimal solution을 $q^*_j(\mathbf{Z}_j)$으로 명시하겠습니다.
$$\begin{align} ln(q^*_{j}(\mathbf{Z}_j)) &= E_{i \ne j} [ln (p(\mathbf{X,Z}))] + \text{const2} \\ &= \int ln(p(\mathbf{X}, \mathbf{Z})) \Pi_{i\ne j}q_j d\mathbf{Z}_i + \text{const2} \end{align}\tag{4}$$
Optimal solution $q^*_j(\mathbf{Z}_j)$은 모든 stochastic variable $\mathbf{Z}$과 observed variable $\mathbf{X}$의 joint distribution $p(\mathbf{X,Z})$를 고려하며 $i \ne j$인 모든 $\{q_i\}$에 대한 기대값을 취합니다.
즉, 개별 $q_j$에 대한 해를 찾을 때 $\{q_i\}, i \ne j$에 의존합니다.
모든 $q_i, \, i=1,2,\cdots, M$을 적절하게 초기화시킨 후, 특정 수렴 조건을 만족할 때까지 iteratively하게 업데이트 해야 합니다.
최종적인 normalized optimal minimum $q^*_j (\mathbf{Z}_j)$는 다음과 같습니다.
$$q^*_j(\mathbf{Z}_j) = \dfrac{exp(E_{i \ne j} [ln(p(\mathbf{X,Z}))])}{\int exp(E_{i \ne j} [ln(p(\mathbf{X,Z})) ])d\mathbf{Z}_j}$$
- $\text{const2} = \int E_{i \ne j} [ln(p(\mathbf{X,Z})])d\mathbf{Z}_j$
True posterior distribution $p(\mathbf{Z}|\mathbf{X})$의 approximation distribution $q(\mathbf{Z})$를 factorized approximation을 사용해 구하였습니다.
$$q^*(\mathbf{Z}) = \Pi^M_{j=1} q^*_j(\mathbf{Z}_j)$$
마지막으로 VI 예시를 다루고 마치도록 하겠습니다.
Example: Univariate Gaussian Distribution
데이터 $D = \{x_1,x_2, \cdots, x_N\}, \, x_i \sim N(\mu,\tau^{-1})$가 주어졌으며 각 객체들은 independently(독립)이라고 가정하겠습니다.
▶ Purpose
모수 $\mu$와 $\tau$에 대한 사후 분포를 variational inference를 통해 추정하고자 합니다.
✅ Likelihood
$$p(D|\mu, \tau) = (\dfrac{\tau}{2 \pi})^{\frac{N}{2}} exp \{- \dfrac{\tau}{2} \sum^N_{n=1} (x_n - \mu)^2\}$$
✅ (Conjugate) Prior Distribution
$$\mu|\tau \sim N(\mu_0, (\lambda_0 \tau)^{-1})$$
$$\tau \sim Gamma(a_0, b_0)$$
✅ Factorized variational approximation
True posterior distribution의 approximation distribution $q_{\mu}(\mu), q_{\tau}(\tau)$을 구하고자 합니다.
$$q(\mu,\tau) = q_{\mu}(\mu)q_{\tau}(\tau)$$
optimal solution을 구하는 식 $(4)$를 이용하여 $\mu$와 $\tau$의 approximation distribution을 구하면 다음과 같습니다.
✅ $\mu^*$: $\mu$의 approximation distribution
$$\begin{align*}\ln q_\mu(\mu) &= \mathbb{E}_\tau \left[ \ln p(D|\mu, \tau) + \ln p(\mu|\tau) \right] + \text{const}
\\
&= -\frac{\mathbb{E}[\tau]}{2} \left( \lambda_0 (\mu - \mu_0)^2 + \sum_{n=1}^N (x_n - \mu)^2 \right) + \text{const}
\end{align*}
$$
$$\mu^* \sim N(\mu_N, \lambda^{-1}_N)$$
$$\mu_N = \dfrac{\lambda_0 \mu_0 + N \bar{x}}{ \lambda_0 + \mu_0}, \lambda_N = (\lambda_0 + N) E[\tau]$$
✅ $\tau^*$: $\tau$의 approximation distribution
$$\begin{align*}
\ln q_\tau(\tau) &= \mathbb{E}_\mu \left[ \ln p(D|\mu, \tau) + \ln p(\mu|\tau) \right] + \ln p(\tau) + \text{const}
\\
&= (a_0 - 1)\ln \tau - b_0 \tau + \frac{N}{2} \ln \tau - \frac{\tau}{2} \left( \sum_{n=1}^N (x_n - \mu)^2 + \lambda_0 (\mu - \mu_0)^2 \right) + \text{const}
\end{align*}$$
$$\tau^* \sim Gamma(a_N, b_N)$$
$$a_N = a_0 + \dfrac{N}{2}, \, b_N = b_0 + \frac{1}{2} \mathbb{E}_\mu \left[ \sum_{n=1}^N (x_n - \mu)^2 + \lambda_0 (\mu - \mu_0)^2 \right]$$
✅ optimal distribution of $q_{\mu}(\mu), q_{\tau}(\tau)$ 모두 서로간의 분포에 의존하는 것을 알 수 있습니다.
$$q(\mu, \tau) = q^*_{\mu}(\mu) q^*_{\tau}(\tau)$$
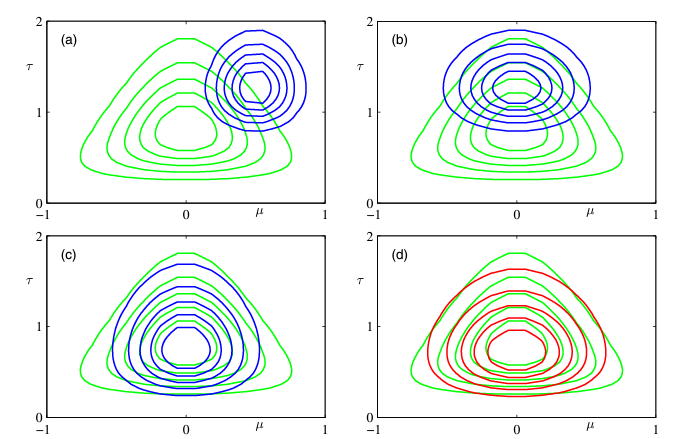
초록색 선은 true posterior distribution $p(\mu, \tau | D)$입니다.
- (a). $q_{\mu}$와 $q_{\tau}$를 초기화한 결과입니다.
- (b). $q_{\mu}$를 re-estimating한 결과입니다.
- (c). re-estimaing된 $q_{\mu}$를 기반으로 $q_{\tau}$를 re-estimating한 결과입니다.
- (d). 특정 수렴 조건에 만족할 때까지 $q_{\mu}$와 $q_{\tau}$를 re-estimating한 결과입니다.
✅ 즉, 수렴할 때까지 두 분포는 계속해서 re-compute(or update, re-estimating) 되어야 합니다.
'Statistics' 카테고리의 다른 글
| Peak Over Threshold(POT)와 Epsilon Threshold (0) | 2024.02.11 |
|---|---|
| Generalized Linear Model For Count Time Series (0) | 2023.12.11 |
| Oracle P-values and variable screening (0) | 2022.11.27 |


